typescript中导入koa-error后报错
无法重新声明块范围变量“onerror”
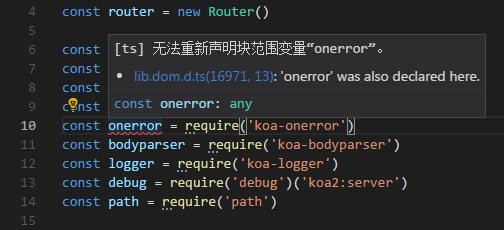
解决办法:打开tsconfig.json中的"lib": ["es2015", "es2016", "es2017"]
无法重新声明块范围变量“onerror”
解决办法:打开tsconfig.json中的"lib": ["es2015", "es2016", "es2017"]
win10家庭版本身不支持组策略,但还是有办法让其支持。 复制下面内容到文本文件:
@echo off
pushd "%~dp0"
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >List.txt
dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientTools-Package~3*.mum >>List.txt
for /f %%i in ('findstr /i . List.txt 2^>nul') do dism /online /norestart /add-package:"C:\Windows\servicing\Packages\%%i"
pause
后缀名保存为cmd,以管理员身份执行:
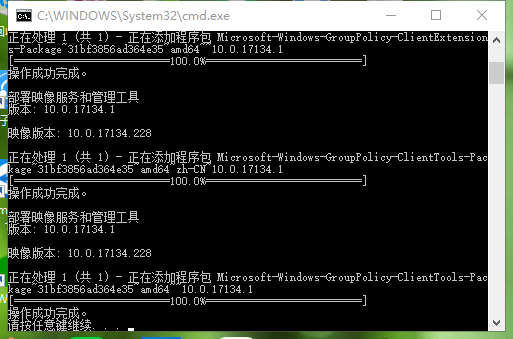
然后WIN+R中执行gpedit.msc即可打开组策略。
如此可以关闭占用CPU过高的Windows Defender。
要说前端界的发展速度,那真是快!
2012年那时候接触过extjs,用于企业级后台开发还真不错,有好看的UI界面,组件丰富,基本能满足各类需求。但此时,HTML5正在蓬勃发展,尤其是乔布斯宣布苹果设备不支持flash后HTML5发展更是迅猛。并且angularjs这类MVVM框架被大多数所知,reactjs,vuejs如雨后春笋般生长。
2014年使用了一段时间angularjs,感觉学习难度有点大,并且据官方说2.0下向下兼容于是放弃继续学习。2015年使用vue1.0做了一个项目后我逢人便说angular,vue有多好用,推荐他们放弃jquery使用vue。不到2年时间再看看前端界,vue,react等框架已经是前端开发标配,如果你说公司项目还在使用jquery会被人笑话,对于前端新人MVVM框架是必学,jquery反而不会被重视。
这就导致一个结果:**“手里拿着锤子,看什么都是钉子”,因为有锤子的关系,遇到任何问题,都会先想如何用锤子解决。久而久之,陷入了一种思维定式。任何工具带来便利的同时,也带来了局限性。而这往往是用锤子的人很难看到的。**就拿一个需要SEO的网站来说,该选择哪种技术好?如果只会vue,那么肯定是选择vue,就算vue不太适合做这类网站,也会拿出ssr来强行做事。殊不知需要SEO的网站使用静态文件是最合适的。大多数人认为前后端分离是使用vue,react,angular,使用jquery的不叫前后端分离,这完全是搞混了概念,实际上后端的controller层也属于视图层,也可以归属于前端。
现在去网上一搜,问一下身边的人怎么看待前后端分离的,大多数人秉持着支持的态度,认为前后端分离好处多多,列举几条:
等等……

大家说的都说到点上了,这也是前后端分离能发展起来的驱动力。但是道理说的都挺好,如果不结合实际情况的话就是大炮打蚊子,不但达不到理想的效果还浪费资源。而且前后端分离带来的负面情况也不可忽视:
那么到底该不该进行前后端分离,如何进行技术选型?这需要根据一些实际情况来决定,大体判断准则有以下几点:
最后,前后端分离是一个趋势,但不是必须。更准确的说法应该叫做“前后端分工”,毕竟在5年前这些活都是一个开发来做的,因为技术复杂性提升,前端不想只是切图,后端不想学变化太快的前端就出现了分离。你可以想象测试的工作,现在的测试大多还是测业务,但是也出现了一个自动化测试的职位,因为测试不想天天鼠标点呀点的测,想搞点高深的东西,而开发又特别烦写单元测试代码,这就又出现分离。再者,数据库也是一样,所以出现了DBA这个角色。谁知哪一天又会合起来呢!
go可以很容易实现一个文件服务器,只需要使用函数
func ServeFile(w ResponseWriter, r *Request, name string)即可。
package main
import (
"log"
"net/http"
"fmt"
)
func helloHandler(res http.ResponseWriter, req *http.Request) {
http.ServeFile(res, req, "E:/go-work/src/go-learning/foo.xlsx")
}
func main() {
fmt.Println("web服务启动成功,可在浏览器中访问:localhost:8081")
http.HandleFunc("/file", helloHandler)
http.Handle("/", http.FileServer(http.Dir("E:/go-work/src/go-learning/")))
err := http.ListenAndServe(":8081", nil)
if err != nil {
log.Fatal("ListenAndServe:", err.Error())
}
}
查看go文档除了翻墙访问https://golang.org
还可以访问国内镜像:https://golang.google.cn/
最简单快速的访问,直接在本地起服务:
godoc -http=:8082
//上传图片
var imagesBase64 = [];
$("input[type=file]").on("change", function (e) {
var image = e.target.files[0];
var imgFile = new FileReader();
var imgShow = new Image();
imgFile.readAsDataURL(image);
imgFile.onload = function () {
var imgData = this.result; //base64数据
imagesBase64.push({
teaId: teacherInfo.id,
fileType: "award",//图片
fileName: image.name,
file: imgData,
});
imgShow.src = imgData;
imgShow.style.width = "100px";
imgShow.style.height = "100px";
imgShow.title = "双击删除";
$("#imageShow").append(imgShow);
}
});
$("#imageShow").on("dblclick ", "img", function () {
var index = $("#imageShow > img").index(this);
console.log(index);
$(this).remove();
imagesBase64.splice(index);
console.log(imagesBase64)
});
修改terminal
apt-get update更新软件源,安装zsh,设置默认terminal为zsh,chsh -s /usr/bin/zsh。非root用户需要在root权限下修改/etc/passwd文件才能实现。
安装git
apt-get install git
nginx设置:
sudo /etc/init.d/nginx restart # or start, stop
或
sudo service nginx restart # or start, stop
有时候我们改了配置文件只是要让配置生效,这个时候不必重启,只要重新加载配置文件即可。sudo nginx -s reload
目录/etc/nginx/sites-available/下增加文件配置反向代理,并软链接到/etc/nginx/sites-enabled/下
mongodb导入数据 启动:
/usr/local/mongodb/bin/mongod –dbpath=/usr/local/mongodb/data –logpath=/usr/local/mongodb/logs –logappend –auth –fork
如需外网客户端连接加参数--bind_ip_all
导入单个collection
./mongorestore -v -h ip -u xxxx -p xxxx –db=blogs -c blogs /home/yuedun/download/xxxx.bson/xxxx/blogs.bson
或导入整个目录
./mongorestore -v -h ip -u xxxx -p xxxx –db=blogs –drop /home/yuedun/download/xxxx.bson/xxxx
没有指定-h参数会报错:Failed: error connecting to db server: no reachable servers
阿里云上-h参数需要内网ip,localhost不行。
“过早的优化是万恶之源”,这句话或多或少在哪听过,不过为什么优化也会带来问题,恐怕只有经历过的人才能理解其中的意义。
关于程序优化,产品优化这些词在开发工作中一定有经历过。某位程序员做事一丝不苟,对程序开发特别注重性能问题,花大量时间来优化某段代码。某位产品在提出需求的时候总是有一些目前用不到的功能,说是为了方便将来扩展。
那么实际工作中这种优化到底起到了什么作用?个人认为弊多于利。
甲同学在做一个员工日常工作内容列表的接口时,认为该接口会产生性能问题,将来数据增多的时候会有性能瓶颈,于是利用了某项缓存技术,觉得缓存一定比直接查数据库速度快,于是就引入了缓存数据库。把数据拉到缓存中,先从缓存中读取数据,没有数据的时候从数据库中读取放到缓存中。这个思路看似挺好,不过为了更新数据就设置过期时间为1天。上线后发现很多员工的日常工作内容一天内会有变化,就设置过期时间为半天,结果半天过期时间还是会有部分员工工作内容更新频繁。这时候就有些纠结了,到底是再降低过期时间还是单独更新某个员工的数据?如果选择降低过期时间会导致所有数据都要从数据库重新拉取,选择单独更新又要对各个更新几口进行修改来更新缓存。这期间不免要折腾几回来适应业务需求,而且容易造成各个业务过度依赖缓存,为了保持缓存数据一致性需要做很多工作,然而很多的工作目的并没有提高系统可用性。
有些同学在设计数据库的时候总喜欢多加些字段,为了方便未来使用,知道索引能加速查询,就使劲加索引,这基本属于不够成熟的思想,试问:等真正需要字段的时候加会晚吗?现在提前加了后面还能知道这个字段当初是准备怎么用来的吗?别的同学要加的时候发现已经有了一个类似的,这个字段到底有没有在用,不敢删又不敢用。索引加了一大堆本以为有积极作用,可不知道索引会占用空间,插入修改却慢了下来。
在没有真实QPS数据和准确预估的情况,开发同学生生怕线上出现故障,要求多部署几台服务器做负载均衡,反正服务器多了也不会有问题。但是过多的服务器会带来其他方面的问题: 1、运维难度增加 2、企业成本增加 3、线上故障排查难度增加
在避免过度设计的情况下才进行针对性优化。性能问题的出现并不是经常性的,而是在某个访问高峰期出现,这时候影响范围还不是很大,但是该考虑进行优化了,如果是经常性突发并发数增加可以考虑缓存数据库。如果是日常单机承载能力高可以进行一定压力测试,评估并发压力增加合适的服务器。随着企业发展,数据量不断累积,此时数据库成为主要压力,此时对数据库索引,SQL进行优化,往往能有立竿见影的效果。
总结:没有针对性的性能优化,只是按照假象场景来设计,最后不但不能起到优化作用反而为后期优化带来累赘。
消息队列(MQ)在系统架构中发挥了重要作用,其主要作用有系统解耦,流量削峰,异步消息存储,分布式系统最终一致性等。 本文介绍的是消息系统中消息发布者和订阅者间参数如何约定和传递?实际应用场景中,一种消息的发布者和订阅者都有可能是多个,也就是多对多的关系,这样就形成了消息参数传递的复杂性,就算一开始参数有约定,大家都按照最初约定来开发,但不免开发过程中各端需求变化带来的修改。例如最开始为了实现系统解耦而引进了消息队列,此时消息参与者较少,只有一个发布者和一个订阅者,这种情况最简单(其实最简单还是直接调接口),双方简单约定了需要传递的参数。
{
userId:123,
userName:"阿离",
age:23
}
后来订阅方又需要性别,地址,工作等信息,要求发布方加参数,这种要求也不过分,那就加好了。
{
userId:123,
userName:"阿离",
age:23,
gender:"女",
address:"上海",
job:"测试"
}
再后来又有一个订阅者参与进了消息系统,要求在上述参数中再加“工作年限”参数,那么先不说什么了,加呗。
{
userId:123,
userName:"阿离",
age:23,
gender:"女",
address:"上海",
job:"测试",
workingLife:4
}
再后来又有不同的订阅者参与进消息系统,每个订阅者都可能有自己的参数要求,参数类型不同,随着系统的发展,连发布者也有多个。这时最初的文档或约定已经不奏效了,总会有人不能及时更新文档导致约定不能成为约束,各自为政,比如“学历”参数有的人要求叫“硕士”,有人要叫“研究生”,总之是很难统一。如果要继续修改发布参数就会有很多冗余出现,参数类型不统一出现系统故障。
这时消息系统已经不是当初简单的两个发布者订阅者了,而是一群人在参数,所谓的众口难调。此时弊端已现,无论哪一方有变化都势必牵连所有人。所以看出的出这种消息参数传递有其不合理的地方,那么怎么传递更合理?此处的MQ最开始已经说了,是为了解耦而引进,说明该MQ是多个系统的衔接者,而多个系统终究还是系统,不是简单的前端和后端接口调用,例如某个前端A也是由自己的接口提供服务系统的,MQ不是直接为前端A提供参数的。应该是由前端A自己的服务端A订阅消息,前端A需要什么参数就有服务A查询需要的参数即可,前端B需要什么参数由服务B查询提供。而发布者A,发布者B等只需要传递关键参数userId即可,其他姓名,性别,年龄什么的都不需要传。
此时有人喜欢拿性能来说事,觉得应该由发布者一次性查出来传递并(作为日志)存储,订阅者不用每次都查询那么多相同参数,这是没理解MQ的意义,MQ应该是负责告诉其他人发布者做了什么,而不应该由订阅者决定发布者和MQ应该怎么做。因为既然是解耦系统,那么各个系统有不同需求,也可能有自己的数据库,就算是要记录日志也是由各系统自己负责存储,不应该由MQ来存储,如果所有参数都由发布者来查询那是不是会降低发布者的性能?就像上面的情况,MQ的参数随着各端要求不断增减,类型变化,最后存储的参数会变得乱七八糟,根本无法使用。
总结:消息队列应该只传递和存储关键信息,如ID就足够了,如果传递多余信息而造成不一致也会出现扯皮的事。各个订阅方自己负责其他参数查询和日志存储,否则就不是解耦了。
beego注解路由匹配不到,返回404页面 router.go使用了两种方式注册路由:
ns := beego.NewNamespace("/admin",
beego.NSRouter("/", &controllers.UserController{}, "get:Welcome"),
beego.NSInclude(
&controllers.UserController{},
),
controller中的路由注解设置:
// @router /admin/user/get-all-user [get]
func (c *UserGroupController) GetAllUser() {
user := new(User)
users, err := user.GetUserList()
if nil != err {
c.Data["json"] = ErrorMsg(err)
}
c.Data["json"] = users
c.ServeJSON()
}
使用上面的方式注册路由后结果是nomatch
最终结果显示上面的注解路由时错误的,下面是正确的注册方式:
问题在于controller的注解写法,如果该路由在namespace下,则不能在注解中拼接命名空间前缀,框架会自动拼接。
即/admin为命名空间,注解中只需写/user/get-all-user,不能这样写/admin/user/get-all-user
// @router /user/get-all-user [get]
func (c *UserGroupController) GetAllUser() {
user := new(User)
users, err := user.GetUserList()
if nil != err {
c.Data["json"] = ErrorMsg(err)
}
c.Data["json"] = SuccessData(users)
c.ServeJSON()
}
当然,两种路由注册的方式可以同时
go语言可以很轻松的实现并发获取数据,就算是新手也可以按部就班的套用现成的并发模式来实现并发。以下是一个简单的测试程序,其中有串行,并行。
package main
import (
"sync"
"time"
"fmt"
)
func main() {
syncFunc()
fmt.Println(">>>>>>>>>>>>>>>")
asyncFunc()
fmt.Println(">>>>>>>>>>>>>>>")
asyncChanFunc()
}
// 串行执行
func syncFunc() {
var n,m,x int
start := time.Now()
fmt.Println("syncFunc start:",start)
func () {
time.Sleep(time.Second*1)
n = 1
}()
func () {
time.Sleep(time.Second*2)
m = 2
}()
func () {
time.Sleep(time.Second*3)
x =3
}()
t := time.Now()
fmt.Println(t)
elapsed := t.Sub(start)
fmt.Println("syncFunc end:", elapsed, n, m, x)
}
// 并行执行
func asyncFunc() {
var n,m,x int
var wg sync.WaitGroup
wg.Add(3)
start := time.Now()
fmt.Println("asyncFunc start:", start)
go func () {
defer wg.Done()
time.Sleep(time.Second*1)
n = 1
}()
go func () {
defer wg.Done()
time.Sleep(time.Second*2)
m = 2
}()
go func () {
defer wg.Done()
time.Sleep(time.Second*3)
x = 3
}()
wg.Wait()
t := time.Now()
fmt.Println(t)
elapsed := t.Sub(start)
fmt.Println("asyncFunc end:", elapsed, n, m, x)
}
// 并行执行
func asyncChanFunc() {
var n, m, x =make(chan int),make(chan int),make(chan int)
start := time.Now()
fmt.Println("asyncChanFunc start:",start)
go func () {
time.Sleep(time.Second*1)
n <- 1
}()
go func () {
time.Sleep(time.Second*2)
m <- 2
}()
go func () {
time.Sleep(time.Second*3)
x <- 3
}()
fmt.Printf("n:%d, m:%d, x:%d\n",<-n, <-m, <-x)
t := time.Now()
fmt.Println(t)
elapsed := t.Sub(start)
fmt.Println("asyncChanFunc end:", elapsed)
}
测试结果: